
L’utilisation d’une API est la solution à privilégier pour récupérer de la donnée, mais quand elle n’existe pas, est incomplète, ou qu’elle est soumise à des limitations trop contraignantes, le scraping du site web associé peut constituer une bonne alternative.
Ce qu’on appelle scraping, c’est la collecte (via l’écriture de bots qu’on appelle scrapers) d’informations ciblées présentes sur un ensemble de pages web. Un scraper est conçu spécifiquement pour un site donné, contrairement à un crawler qui sera plus généraliste (le comparateur de prix Google Shopping utilise des scrapers quand le moteur de recherche Google utilise des crawlers).
Les usages sont multiples (agrégation d’annonces de plusieurs jobboards, veille concurrentielle, …), et ne sont pas forcément réservés au monde professionnel.
Nous pouvons en effet trouver plusieurs situations où l’écriture d’un scraper perso peut avoir son intérêt:
- Envoyer un mail dès que les devoirs ont été mis à jour sur le blog de l’école des enfants
- Avancer automatiquement le réveil d’un quart d’heure lorsqu’un site de météo prévoit du verglas le lendemain matin
- Recevoir une notification lorsque le prix d’un article sur un site de e-commerce passe en dessous d’un certain seuil
Je vous propose d’illustrer ce dernier cas d’usage.
Recherche Raspberry Pi 4, pas cher, …
Prenons ce Raspberry Pi 4B sur www.kubii.fr, il est en vente à 83.99€ mais nous aimerions attendre qu’il passe en dessous des 75€ avant de passer commande. Comme une baisse de prix peut vite conduire à une rupture de stock, autant être prévenu rapidement pour éviter de passer à côté d’une bonne affaire.
L’information que nous cherchons à collecter ici, c’est le prix de l’article:
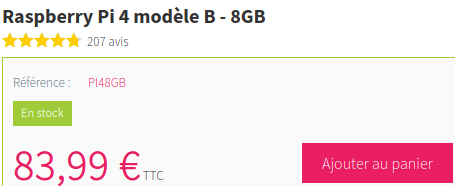
Regardons ce que ça donne au niveau du HTML:
<p class="our_price_display" itemprop="offers" itemscope="" itemtype="https://schema.org/Offer">
<link itemprop="availability" href="https://schema.org/InStock">
<span id="our_price_display" class="price" itemprop="price" content="83.99">83,99 €</span> TTC
<meta itemprop="priceCurrency" content="EUR">
</p>
A partir de là, il nous faut trouver un point d’ancrage, c’est à dire un critère qui permettra de retrouver le prix (soit l’attribut content de la balise span) à coup sûr et sans doublon.
Après analyse de la page complète il s’avère que l’attribut itemprop="price" est en bon candidat (on ne trouve qu’une seule balise span répondant à ce critère).
Notre scraper (en go) va donc pouvoir prendre forme:
package main
import (
"github.com/PuerkitoBio/goquery"
"log"
"net/http"
"strconv"
"time"
)
func main() {
goodPrice := false
// On boucle tant qu'on n'est pas passé en dessous de notre seuil
for !goodPrice {
// Chargement de la page du produit
res, err := http.Get("https://www.kubii.fr/cartes-raspberry-pi/2955-raspberry-pi-4-modele-b-8gb-0765756931199.html")
if err != nil {
log.Printf("Page inaccessible, on retentera plus tard: %v", err)
time.Sleep(30 * time.Minute)
continue
}
if res.StatusCode != 200 {
res.Body.Close()
log.Printf("Page inaccessible, on retentera plus tard, status code: %d", res.StatusCode)
time.Sleep(3 * time.Hour)
continue
}
// Parsing du html via goquery
doc, err := goquery.NewDocumentFromReader(res.Body)
res.Body.Close()
if err != nil {
log.Panicf("Impossible d'interprêter le HTML: %v", err)
}
// Recherche du prix
var priceStr string
var ok bool
if priceStr, ok = doc.Find("span[itemprop='price']").Attr("content"); !ok {
log.Panicf("Prix introuvable, il faut mettre à jour le scraper")
}
// Conversion du prix en float64
price, err := strconv.ParseFloat(priceStr, 64)
if err != nil {
log.Panicf("Impossible de lire le prix, il faut mettre à jour le scraper")
}
if price >= 75 {
log.Printf("%0.2f € c'est encore trop cher!", price)
} else {
log.Printf("Seulement %0.2f €, go go go!!!", price)
// TODO: Envoi d'un mail, d'un SMS, appel d'un webhook discord, déclenchement de l'alarme, clignotement des ampoules connectées, etc ...
goodPrice = true
}
// On retente dans 30 minutes
time.Sleep(30 * time.Minute)
}
log.Printf("Merci pour ce moment")
}
La logique est somme toute assez simple
- Toutes les 30 minutes, nous récupérons le prix jusqu’à ce qu’il passe en dessous des 75€, le cas échéant nous levons une alerte.
- Une gestion basique (et perfectible!) des indisponibilités de la page produit est appliquée, qu’elles soient:
- de notre fait (coupure réseau, … ) => nouvelle tentative au bout de 30 minutes
- ou de celui du site (maintenance, défense anti-bot, …) => nouvelle tentative au bout de 3 heures (inutile de s’acharner)
- Si le prix n’est plus récupérable, nous partons du principe que le site a dû être mis à jour et que notre point d’ancrage a dû sauter par la même occasion, nous devons donc en trouver un nouveau et mettre à jour le traitement en conséquence.
A noter que la recherche de la fameuse balise <span> contenant notre prix se fait aisément via l’excellente librairie goquery, qui permet comme en javascript d’utiliser les sélecteurs CSS pour localiser des éléments du DOM.
Pour finir
Un petit VPS, un NAS, un vieux Raspberry PI qui traîne (d’où l’achat d’un nouveau!) ou simplement votre PC (si vous êtes du genre à le garder allumé H24), et vous voilà paré pour déployer votre premier scraper.
N’hésitez pas à adapter cet exemple à vos besoin, mais veillez tout de même à rester raisonnable sur la fréquence des requêtes, certains sites n’aiment pas les bots qui monopolisent trop de ressources sur leur serveur au détriment des vrais visiteurs. Vous pouvez donc les comprendre s’ils finissent par blacklister votre IP du fait que vous tentez de récupérer un prix toutes les 2 secondes au lieu de 30 minutes, à bon entendeur…😉