
The use of an API is the preferred solution to retrieve data, but when it does not exist, is incomplete, or is subject to limitations that are too restrictive, scraping the associated website can be a good alternative.
What we call web scraping is the collection (via the writing of bots called scrapers) of targeted data present on a set of web pages. A scraper is designed specifically for a given site, unlike a crawler which will be more generalist (Google Shopping uses scrapers when Google (aka the search engine) uses crawlers).
The uses are multiple (aggregation of ads from several job boards, competitive intelligence, …), and are not necessarily reserved to the professional world.
We can indeed find several situations where writing a personal scraper can have its interest:
- Sending an email as soon as the homework has been updated on the children’s school blog
- Automatically setting the alarm clock 15 minutes earlier when a weather site forecasts ice the next morning
- Receive a notification when the price of an item on an e-commerce site falls below a certain threshold
Let’s illustrate this last use case.
Looking for a cheap Raspberry Pi 4
Let’s take this Raspberry Pi 4B on www.kubii.fr, it is on sale for 83.99€ but we would like to wait until it drops below 75€ before ordering. As a price drop can quickly lead to a stockout, we might as well be warned quickly to avoid missing a good deal.
The information we are looking for here is the price of the item:
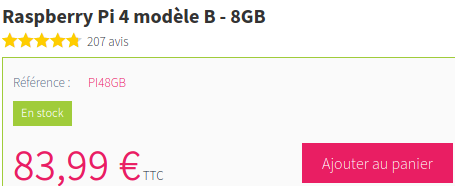
Let’s see how it looks in the HTML:
<p class="our_price_display" itemprop="offers" itemscope="" itemtype="https://schema.org/Offer">
<link itemprop="availability" href="https://schema.org/InStock">
<span id="our_price_display" class="price" itemprop="price" content="83.99">83,99 €</span> TTC
<meta itemprop="priceCurrency" content="EUR">
</p>
From there, we need to find an anchor point, that is to say a criterion that will allow us to find the price (i.e. the attribute content of the span tag) for sure and without duplication.
After analyzing the complete page, it turns out that the itemprop="price" attribute is a good candidate (we only find one span tag meeting this criterion).
Our scraper (in go) can now take shape:
package main
import (
"github.com/PuerkitoBio/goquery"
"log"
"net/http"
"strconv"
"time"
)
func main() {
goodPrice := false
// Stay in the loop as long as we have not passed below our threshold
for !goodPrice {
// Loading of the product page
res, err := http.Get("https://www.kubii.fr/cartes-raspberry-pi/2955-raspberry-pi-4-modele-b-8gb-0765756931199.html")
if err != nil {
log.Printf("Unable to load the product page, we will try again later: %v", err)
time.Sleep(30 * time.Minute)
continue
}
if res.StatusCode != 200 {
res.Body.Close()
log.Printf("Unable to load the product page, we will try again later, status code: %d", res.StatusCode)
time.Sleep(3 * time.Hour)
continue
}
// HTML Parsing through goquery
doc, err := goquery.NewDocumentFromReader(res.Body)
res.Body.Close()
if err != nil {
log.Panicf("Unable to parse HTML content: %v", err)
}
// Price retrieval
var priceStr string
var ok bool
if priceStr, ok = doc.Find("span[itemprop='price']").Attr("content"); !ok {
log.Panicf("Price not found, scraper should be updated")
}
// Price conversion
price, err := strconv.ParseFloat(priceStr, 64)
if err != nil {
log.Panicf("Unable to read the price, scraper should be updated")
}
if price >= 75 {
log.Printf("%0.2f € it's still too expensive!", price)
} else {
log.Printf("Only %0.2f €, go go go!!!", price)
// TODO: Sending an email, an SMS, calling a discord webhook, triggering the alarm, flashing the connected bulbs, etc ...
goodPrice = true
}
// We try again in 30 minutes
time.Sleep(30 * time.Minute)
}
log.Printf("Done!")
}
The logic is quite simple
- Every 30 minutes, we retrieve the price until it falls below 75€, if necessary we raise an alert.
- A basic (and perfectible!) management of the unavailability of the product page is applied, whether they are
- due to us (network failure, … ) => new attempt after 30 minutes
- or due to the site (maintenance, anti-bot defense, …) => new attempt after 3 hours (no need to be stubborn)
- If the price is no longer retrievable, we assume that the site must have been updated and that our anchor point must have jumped at the same time, so we must find a new one and update the scraper accordingly.
Note that the search for the famous <span> tag containing our price is easily done via the excellent goquery library, which allows, as in javascript, to use CSS selectors to locate DOM elements.
Finally
A small VPS, a NAS, an old Raspberry PI (hence the purchase of a new one!) or simply your PC (if you’re the kind of person who keeps it on 24 hours a day), and you’re ready to deploy your first scraper.
Feel free to adapt this example to your needs but, word to the wise, be sure to stay reasonable on the frequency of requests, some sites do not like bots that monopolize too many resources on their server to the detriment of real visitors. So you can understand them if they end up blacklisting your IP because you try to retrieve a price every 2 seconds instead of 30 minutes…